Here’s an excerpt from my new book, Quantitative Investment Portfolio Analytics In R: An Introduction To R For Modeling Portfolio Risk and Return, which was published last week. In this two-part excerpt of Chapter 5, we’ll look at a basic procedure for downloading factor premia from Professor Ken French’s web site to run a simple factor analysis using R code. I’ll publish the second half of Chapter 5’s excerpt soon. (Note: for a cleaner read, the footnotes that appear in the book have been removed for this web-based version of the chapter. For a complete list of chapters, see here. Keep in mind that all the code published in Quantitative Investment Portfolio Analytics In R can be accessed via a single file by way of a link that’s published in the book.)
Chapter 5 (part I)
Factor Analysis
Most investment portfolios are a collection of risk factors, such as exposure to
credit and equity risk, a.k.a. corporate bonds and stocks. Targeting specific factors
may or may not be the intent, but the risk-factor profile is always a crucial
influence on portfolio results. Accordingly, monitoring and managing these
factors is critical.
The standard approach is reviewing portfolios through a plain-vanilla asset
allocation lens – 60% stocks, 30% bonds, 10% cash, for instance. But the standard
methodology is a blunt instrument. For a clearer view of what’s driving a
portfolio, decomposing risk with factor-based analysis offers deeper insight.
The stakes are high because the sources of risk and return in a portfolio can
remain hidden if you’re focused on analyzing a strategy via a conventional asset allocation lens. That’s a problem for the simple reason that if you’re in the dark about the full extent of the risk profile for a strategy, effective risk management is harder and perhaps even impossible. Fortunately, there’s a solution.
Decomposing risk can take many forms. The basic approach is analyzing a portfolio based on its components. A simple risk-contribution profile of component securities, for instance, is usually a good way to begin. But a security based review merely scratches the surface of the possibilities. Knowing that, say, one ETF in your strategy is the source of 60% of the portfolio’s return volatility, or that three funds represent 90% of volatility, is useful information. But every fund represents a mix of factors, which means that you’ll have to go deeper for a complete accounting of risk and return drivers. That’s where factor-based analysis (FBA) comes in.
Conceptually, FBA is straightforward. Select a set of relevant risk factors and regress the portfolio’s returns against the returns of indexes representing the relevant factors. In practice, however, the details can be tricky and so it’s best to have a clear idea of your goals before you start crunching the numbers.
The main issue is selecting the risk factors for the portfolio under scrutiny. This is where most of the heavy lifting takes place. For instance, are you focused on macroeconomic factors, such as inflation, interest rates, and so on? Alternatively, you can emphasize financial factors, such as value and growth for equities or term and default factors for bonds. Or, maybe it’s wise to combine macroeconomic and financial factors.
Although there are some common-sense guidelines to follow, a wide range of customization is possible for factor analysis, depending on the portfolio and investment objective.
5.1 Decomposing S&P 500 Risk With The Fama-French 3-Factor Model
As a toy example, let’s use the Fama-French three-factor model1 to decompose the stock market’s factors via the S&P 500’s monthly returns. The model advises that most of the market’s returns can be quantitatively explained by three factors: market risk; the excess performance of small-cap stocks over large caps; and the outperformance of so-called value stocks, i.e., companies that are underpriced relative to their book value, vs. highly valued shares. The question is whether one or more factors explain a greater or lesser proportion of the returns? Factor analysis offers a quantitative answer.
The first step is to load the equity market’s factor premiums by downloading the data directly from Professor Ken French’s web site and then processing the file for use with factor analysis.
[code language=”r”]
library(xts)
download.file("http://bit.ly/2ikMUxn",
destfile="F-F_Research_Data_Factors.zip", mode=’wb’)
unzip("F-F_Research_Data_Factors.zip")
ff.factors <-read.delim(‘F-F_Research_Data_Factors.txt’,
sep="",
nrows=1067,
header=FALSE,
skip=4,
stringsAsFactors=FALSE)
names(ff.factors) <- c("Date", "MKT", "SMB", "HML", "RF")
ff.factors.3 <-ff.factors[,2:4]
dates.1 <-as.yearmon(as.character(ff.factors$Date), "%Y%m")
ff.factors.dates <-xts(as.matrix(ff.factors.3), as.Date(dates.1))
[/code]
For the S&P 500 returns, we can use the managers file in PerformanceAnalytics and convert the monthly dates to a first-day format with the indexAt='firstof' option in the to.monthly command to match the format in ff.factors.dates. The code below also creates a history of the S&P 500’s risk premia by subtracting the 3-month T-bill’s performance from the equity market’s monthly returns.
[code language=”r”]
library(PerformanceAnalytics)
data(managers)
sp500.ret.tbill <-to.monthly(managers[,c(8,10)],
indexAt=’firstof’,OHLC=F)
sp500.ret.premium <-sp500.ret.tbill[,1] – sp500.ret.tbill[,2]
colnames(sp500.ret.premium) <-c("SP500")
[/code]
We also need to trim the length of the factor premium file to match the relatively short S&P 500 risk premia data in sp500.ret.premium. This is easily accomplished by subsetting based on dates to create ff.factors.subset, as shown below. We then combine the S&P 500 return premiums and the factor premiums in ff.factors.sp500.ret.premium.
[code language=”r”]
sp500.dates <-as.Date(index(sp500.ret.premium))
ff.factors.subset <-ff.factors.dates[paste0(sp500.dates)] * 0.01
ff.factors.sp500.ret.premium <-cbind(ff.factors.subset,
sp500.ret.premium)
[/code]
Now we can perform the linear regression with the lm function, capturing the output in sp500.factors.
[code language=”r”]
sp500.factors <-lm(SP500 ~ ., data=ff.factors.sp500.ret.premium)
[/code]
To review the regression results use summary(sp500.factors). Consider the Estimate column in the Coefficients section that lists the factor loadings, sometimes referred to as betas. The market factor (MKT) scores the highest reading: 0.986. That indicates that the S&P 500 Index’s fluctuations are primarily driven by the broad stock market’s influence – not surprising since the S&P 500 tracks large-cap companies that are widely viewed, in aggregate, as a proxy for the equity market. If the S&P was a perfect match with MKT, the reading would be 1.0. The actual result is only slightly below that level. By contrast, there’s a modestly negative beta for the small-cap factor (SMB) and a near-zero reading for the value factor (HML). The S&P 500, in short, is unlikely to be confused with a small-cap or value index.
[code language=”r”]
summary(sp500.factors)
[/code]
[code language=”r”]
Call:
lm(formula = SP500 ~ ., data = ff.factors.sp500.ret.premium)
Residuals:
Min 1Q Median 3Q Max
-0.014339 -0.002115 0.000032 0.002040 0.012365
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.0001157 0.0003991 0.290 0.7723
MKT 0.9863505 0.0097713 100.944 <2e-16 ***
SMB -0.1802899 0.0102612 -17.570 <2e-16 ***
HML 0.0349246 0.0139871 2.497 0.0138 *
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.00435 on 128 degrees of freedom
Multiple R-squared: 0.9901, Adjusted R-squared: 0.9899
F-statistic: 4274 on 3 and 128 DF, p-value: < 2.2e-16
[/code]
The Adjusted R-squared reading of 0.99 suggests that 99% of the S&P 500’s returns are “explained” by the three Fama-French factors. The low p-values in the far right-hand column (Pr(>|t|) for MKT, SMB, and HML indicate that we can reject the null hypothesis for these factors. In other words, the results aren’t likely to occur due to chance. Accordingly, these factors offer a meaningful lens for deconstructing the S&P 500’s risk profile. If the p-values aren’t statistically significant, we might question the value of the factor analysis.
For a comparison of the model’s estimated risk premia vs. the portfolio’s historical record, the first step is generating fitted data – the product of the factor coefficients and the Fama-French factor data. Once the calculation is complete, plot the data for a visual review.
[code language=”r”]
rp.estimate <-sp500.factors$coefficients[1] +
sp500.factors$coefficient[2] * ff.factors.sp500.ret.premium$MKT +
sp500.factors$coefficient[3] * ff.factors.sp500.ret.premium$SMB +
sp500.factors$coefficient[4] * ff.factors.sp500.ret.premium$HML
plot(as.numeric(sp500.ret.premium ),
as.numeric(rp.estimate),
main="Fama French 3-factor model for S&P 500",
ylab="estimated premia",
xlab="historical premia")
grid()
[/code]
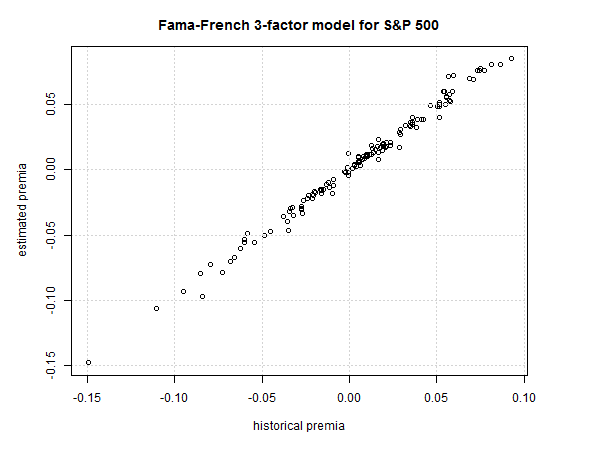
Figure 5.1: Historical vs. expected risk premia for S&P 500

Figure 5.1 shows that the estimated risk premia align closely with actual data and so it’s fair to say that the Fama-French 3-factor model appears to present a reasonably accurate profile of the S&P 500’s returns.
Pingback: Quantocracy's Daily Wrap for 06/28/2018 | Quantocracy
Congrats on the book.
Regarding the specific code: the managers dataset comes only with end of month data in my install while the fama french xts when using as.Date has a start of month date so the subsetting doesn’t work and gives an empty object. When specifying as.Date with the optional argument “frac” of 1 gives end of month dates but by forcing the FF factors to end of month my regression coefficients have no statistical significance
Used: ff.factors.dates <-xts(as.matrix(ff.factors.3), as.Date(dates.1,1))